LLMs represent one of the most groundbreaking advancements in artificial intelligence, transforming how machines understand, generate, and interact with human language. Built on deep learning principles and trained on vast datasets, these models have redefined the possibilities in natural language processing, powering applications across industries such as healthcare, education, finance, and entertainment. From enabling seamless conversations with virtual assistants to generating complex, human-like content, Large Language Models have become indispensable tools in modern AI-driven solutions.
Evolution of Language Models
The journey of language models began with rule-based systems, where linguists and computer scientists manually crafted sets of rules to process and generate human language. These early systems relied heavily on grammar-based algorithms and lacked the ability to learn or adapt, making them rigid and limited in scope. As computational power and data availability increased, statistical methods were introduced in the 1980s and 1990s, marking the shift from rule-based systems to probabilistic models. Techniques like n-grams and Hidden Markov Models (HMMs) enabled machines to analyze language based on probabilities derived from large datasets, improving accuracy and contextual understanding.
The advent of neural networks in the early 2000s marked a significant milestone. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) models were developed to address the sequential nature of language, allowing systems to retain context over longer inputs. These models laid the groundwork for modern language models but were limited by computational constraints and difficulties in processing long-term dependencies.

Milestones Leading to the Development of LLMs
Word Embeddings (2013)
The introduction of word embeddings, such as Word2Vec and GloVe, revolutionized language processing by representing words as vectors in high-dimensional space. This innovation captured semantic relationships between words, making models context-aware.
Sequence-to-Sequence Models (2014)
Seq2Seq architectures enabled the transformation of one sequence of text into another, powering applications like machine translation. These models used RNNs for both encoding and decoding text.
Attention Mechanism (2015)
The attention mechanism improved the handling of long sequences by allowing models to focus on specific parts of the input, addressing limitations of RNNs and LSTMs.
Transformers (2017)
The paper “Attention is All You Need” introduced the transformer architecture, which replaced RNNs with self-attention mechanisms. Transformers became the foundation of large language models, offering superior scalability and efficiency.
BERT (2018)
Bidirectional Encoder Representations from Transformers (BERT) marked a breakthrough by introducing bidirectional context analysis, significantly improving natural language understanding.
GPT Series (2018-2023)
OpenAI’s Generative Pre-trained Transformer (GPT) models popularized large-scale pretraining and fine-tuning. Each iteration (GPT, GPT-2, GPT-3, GPT-4) increased in size and capability, setting benchmarks for language generation and understanding.
Multimodal Models and Fine-Tuning Innovations (2020+)
Recent advancements integrated text with other modalities (e.g., images, audio) and introduced techniques like zero-shot and few-shot learning, broadening the applicability of LLMs to diverse tasks and domains.
| The global LLM market is projected to grow from $1,590 million in 2023 to $259,8 million in 2030. During the 2023-2030 period, the CAGR will be at 79,80%. |
Core Characteristics of Large Language Models
Large Language Models (LLMs) are advanced neural network-based systems trained on massive datasets to understand, generate, and respond to human language with remarkable sophistication. Built on transformer architectures, these models process and produce text with exceptional accuracy and coherence, powered by their immense scale, often featuring billions or trillions of parameters that enable learning and pattern recognition.
Key characteristics of LLMs include pretraining on diverse text corpora to establish a broad understanding of language, followed by fine-tuning for specific tasks such as translation, summarization, or question-answering. They excel in contextual understanding, capturing nuances across long text sequences to handle multi-turn conversations effectively. With increased scalability through larger datasets and computational power, LLMs achieve exponential improvements in functionality and accuracy. Additionally, they demonstrate zero-shot and few-shot learning capabilities, performing tasks with minimal or no prior examples by leveraging their comprehensive language knowledge.
Differentiation from Traditional Language Models
Unlike traditional models such as n-grams and statistical approaches that relied on predefined probabilities and limited context windows, LLMs utilize billions of parameters and advanced architectures to process much larger datasets and capture intricate patterns. Traditional models typically processed text sequentially, often losing context over longer passages, whereas LLMs leverage transformer-based architectures and attention mechanisms to retain and utilize context across extensive text sequences. Earlier models were task-specific and required individual training for different applications, while LLMs, pre-trained on diverse datasets, generalize across tasks and excel in unseen challenges with little or no additional training.
The output quality of traditional models was often repetitive or irrelevant, whereas Large Language Models produce coherent, contextually appropriate, and human-like text, making them highly effective in real-world applications. Additionally, LLMs employ training methodologies, such as transfer learning and reinforcement learning from human feedback (RLHF), to continuously improve performance—capabilities that traditional models lacked. This ability to understand and generate language at scale positions LLMs as a transformative advancement in artificial intelligence, offering unparalleled flexibility and performance in tasks ranging from text generation to complex problem-solving.
Architecture and Mechanisms
The architecture and mechanisms are the foundation of their advanced capabilities in understanding and generating human language. These models leverage neural network designs, sophisticated training methodologies, and vast, diverse datasets to achieve their impressive performance. Each component plays a critical role in shaping the functionality and adaptability of LLMs, enabling them to excel across a wide range of applications.

Neural Network Foundations
Large Language Models (LLMs) are built on deep learning principles, utilizing neural networks to mimic the human brain’s ability to process and analyze information. These models rely on multilayered architectures where each layer processes data and passes it to the next for progressively refined understanding. Transformers, introduced in the landmark paper “Attention is All You Need”, form the backbone of LLMs. Unlike earlier architectures such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, transformers use self-attention mechanisms, allowing the model to weigh the importance of each word in a sequence relative to others. This design significantly improves the handling of context over long passages, enabling LLMs to process language with greater accuracy and efficiency.
Training Methodologies
LLMs undergo a two-step training process: pretraining and fine-tuning. During pretraining, models are exposed to vast datasets to develop a general understanding of language structure, syntax, and semantics. This stage equips LLMs with the ability to predict words and phrases based on context. Fine-tuning follows, where the model is adapted for specific tasks like sentiment analysis, translation, or summarization by training it on task-specific data. Transfer learning plays a critical role in this process, enabling the model to apply knowledge gained during pretraining to new domains or applications with minimal additional training. This approach ensures efficiency, versatility, and the ability to handle diverse language tasks.
Role of Datasets
The effectiveness of LLMs heavily depends on the datasets used during training. These models are trained on vast datasets comprising text from books, articles, websites, and other written sources to ensure a comprehensive understanding of language. The scale of these datasets—often reaching petabytes—is crucial for enabling LLMs to capture complex patterns and rare linguistic phenomena. Diversity in datasets ensures the model can understand various dialects, contexts, and domains, reducing biases and enhancing adaptability. Quality is equally critical, as low-quality or unrepresentative data can introduce inaccuracies or perpetuate harmful biases. Careful curation of datasets, including filtering and balancing, is essential to develop reliable and unbiased Large Language Models capable of delivering accurate and fair outputs.
Prominent Examples of LLMs
Several groundbreaking Large Language Models have revolutionized natural language processing, each excelling in unique ways. The GPT series (Generative Pre-trained Transformer), developed by OpenAI, includes models like GPT-3 and GPT-4, which are renowned for their ability to generate human-like text, summarize content, and handle complex queries across various domains. Google’s BERT (Bidirectional Encoder Representations from Transformers) is designed to understand context by analyzing words bidirectionally, making it highly effective for tasks such as sentiment analysis, question-answering, and text classification.
Meta’s LLaMA (Large Language Model Meta AI) prioritizes efficiency and adaptability, delivering competitive performance with fewer parameters, making it more accessible for specialized applications. PaLM (Pathways Language Model), also developed by Google, is a large-scale model designed for multilingual understanding and reasoning, pushing the boundaries of scale and versatility. Together, these models exemplify the diversity and potential of LLMs, catering to a wide range of tasks and industries while advancing the capabilities of AI.
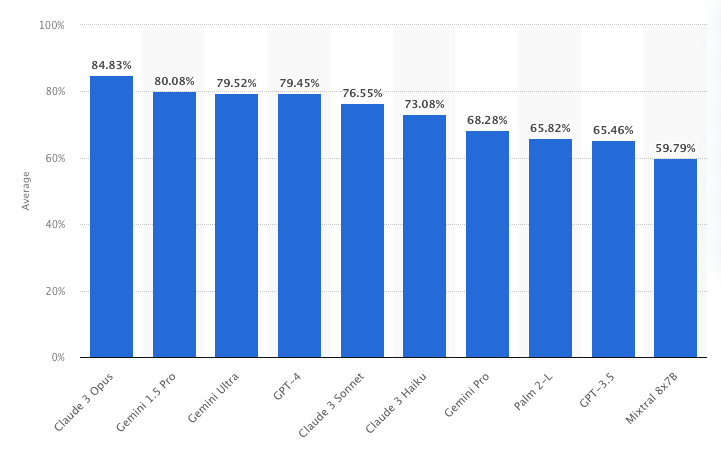
Ranking of large language model (LLM) tools worldwide in 2023
Benefits and Advantages
Large Language Models (LLMs) offer significant benefits that have transformed how AI interacts with human language. One of their primary strengths is their ability to handle complex linguistic tasks, such as understanding idioms, context, and nuanced meanings, enabling accurate translations, summaries, and creative text generation. Their versatility and adaptability allow them to excel across various domains, from healthcare and finance to education and entertainment, addressing diverse challenges like patient record analysis, customer service automation, and personalized learning experiences. Additionally, they enhance personalization and user engagement by leveraging contextual understanding and data insights to deliver tailored responses and recommendations. This capability fosters deeper connections with users, making interactions more meaningful and effective in applications like e-commerce, virtual assistance, and content creation. These advantages position LLMs as indispensable tools in modern AI-driven solutions.
Challenges and Ethical Considerations
One major challenge for Large Language Models is their computational demands and environmental impact, as training these models requires enormous computational resources, resulting in significant energy consumption and a high carbon footprint. This has raised concerns about the sustainability of scaling such models further. Another critical issue is biases inherent in training data, where unbalanced or flawed datasets can lead to outputs that reinforce stereotypes or unfair assumptions, affecting the reliability and inclusivity of these systems.
Ensuring ethical use and preventing misuse is equally important, as these models can be exploited to generate misleading information, impersonate individuals, or create harmful content, posing risks to societal trust and security. Additionally, there are pressing concerns surrounding intellectual property and data privacy, as models often train on vast datasets that may unintentionally include copyrighted or sensitive information, leading to potential legal and ethical complications. Addressing these issues requires transparent development practices, robust data curation, and strict regulatory frameworks to ensure responsible and equitable deployment of Large Language Models.

Future Directions and Innovations
The future of Large Language Modelsis shaped by ongoing advancements aimed at enhancing their scalability, efficiency, and adaptability. One significant trend is scaling and efficiency improvements, where research focuses on creating models that achieve higher performance with fewer resources, addressing the computational and environmental challenges associated with large-scale training. Techniques like sparsity and model distillation are being explored to optimize resource usage while maintaining effectiveness.
Another promising direction is the integration with multimodal systems, which combine text, image, and audio processing capabilities. These multimodal LLMs enable richer and more versatile interactions, such as generating detailed descriptions of images or providing real-time transcription and analysis of video content. This evolution is particularly impactful in fields like healthcare, education, and entertainment.
| By 2025, it’s estimated that there will be 750 million apps using LLMs. |
The development of domain-specific LLMs is gaining traction as industries seek tailored solutions for specialized applications. These models, trained on data specific to a particular field such as medicine, law, or finance, can offer unparalleled accuracy and relevance in niche tasks, reducing the need for broad, generalized models in certain contexts.
There is an increasing emphasis on responsible AI practices and governance, addressing ethical concerns and ensuring fairness, transparency, and accountability in Large Language Models development and use. Efforts include implementing bias mitigation strategies, improving data privacy protections, and establishing regulatory frameworks to govern the ethical deployment of these powerful technologies. Together, these innovations and practices will shape the next generation of LLMs, ensuring they remain impactful, efficient, and aligned with societal needs.
Conclusion
Transformative advancements in AI have enabled sophisticated language understanding and generation across industries. From early rule-based systems to transformer architectures, these models tackle complex tasks like translation, summarization, and natural conversation with remarkable precision. Despite their benefits, challenges such as computational demands, biases, and ethical considerations remain critical to address.
With ongoing progress in efficiency, multimodal integration, and specialized applications, these technologies are set to revolutionize even more fields. Thoughtful adoption and responsible practices will ensure their potential is fully realized to drive innovation and solve pressing global challenges.