Machine learning (ML) is a branch of artificial intelligence (AI) that focuses on creating algorithms capable of learning from data and improving performance over time without being explicitly programmed. These algorithms identify patterns and make predictions or decisions, evolving dynamically as new data becomes available. ML can handle complex and unstructured datasets such as images, text, and audio, making it a critical tool in modern computational systems. With its reliance on statistical models, ML enables automation in tasks previously requiring significant human input, such as language processing, image recognition, and anomaly detection. This adaptability and efficiency make ML essential in addressing contemporary technological challenges and innovation needs.
Importance of Machine Learning
The impact of ML extends across industries, transforming how businesses and organizations operate. In healthcare, ML enhances diagnostic accuracy by identifying diseases in medical images (e.g., X-rays, MRIs) and predicting patient outcomes using historical data. It accelerates drug discovery through advanced algorithms that simulate molecular interactions, significantly reducing time and costs.
In finance, ML improves fraud detection by analyzing patterns in real-time transactions and enables algorithmic trading by processing vast financial datasets with predictive precision. E-commerce relies on ML for tailored user experiences through personalized recommendations, automated customer support (chatbots), and inventory optimization, minimizing overstock and shortages. In manufacturing, ML optimizes predictive maintenance by identifying machine failures before they occur, while in transportation, it underpins autonomous vehicles and efficient logistics. These real-world applications highlight ML’s role in driving efficiency, improving decision-making, and enabling innovation across diverse sectors.
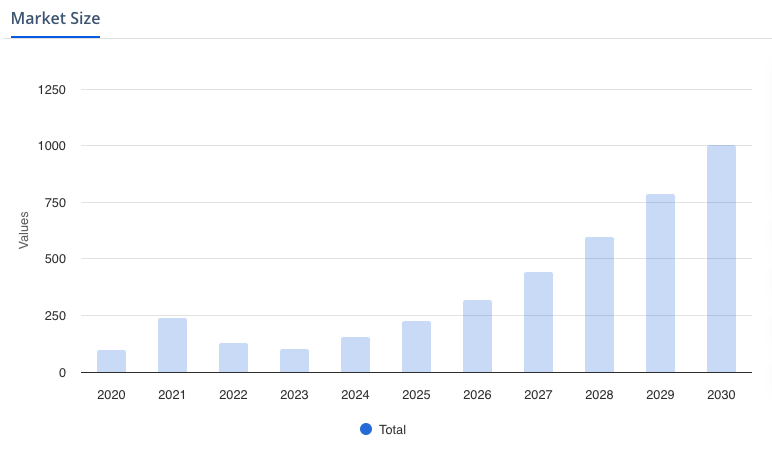
Machine Learning market size projection worldwide
| The market size is expected to show an annual growth rate (CAGR 2024-2030) of 36.08%, resulting in a market volume of US$503.40bn by 2030. |
Key Concepts in Machine Learning
Machine learning encompasses three main types of learning approaches: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning: Involves training models using labeled datasets, where the input data is paired with the correct output. Common algorithms include linear regression, support vector machines, and neural networks. This approach is widely used in tasks such as image classification, sentiment analysis, and fraud detection.
Unsupervised Learning: Works with unlabeled data to identify hidden patterns or structures. Algorithms like K-means clustering and principal component analysis (PCA) are typical. Use cases include customer segmentation, anomaly detection, and data compression.
Reinforcement Learning: Focuses on teaching models to make sequential decisions through trial and error. The model interacts with an environment, learning from rewards and penalties. Applications include robotics, game AI, and autonomous vehicles.
Overview of Algorithms Used in Machine Learning
Machine learning employs a variety of algorithms tailored to specific tasks. Linear regression is used for predicting continuous values, while logistic regression handles binary classification tasks. Decision trees and random forests excel in classification and regression by splitting data into hierarchical structures. Neural networks, inspired by the human brain, are the foundation of deep learning, capable of handling complex tasks such as image recognition and natural language processing. Clustering algorithms like K-means are used for grouping similar data points, while support vector machines (SVMs) are effective in classification tasks with high-dimensional data. Each algorithm offers unique strengths and is chosen based on data type, problem complexity, and performance requirements.
Differences Between Machine Learning and Artificial Intelligence
While machine learning is a subset of artificial intelligence, the two terms are not interchangeable. AI refers to the broader field of creating systems capable of mimicking human intelligence, encompassing areas such as natural language processing, robotics, and expert systems. Machine learning, on the other hand, specifically focuses on building systems that learn and adapt from data without direct human intervention. AI often incorporates machine learning as a component, but it may also use rule-based systems or symbolic reasoning. The distinction lies in scope—AI aims to replicate intelligent behavior broadly, while ML targets data-driven learning to perform specific tasks.

Machine Learning Workflow
A successful machine learning project follows a structured workflow, ensuring that the model is efficient, accurate, and scalable. The key stages include data collection, preprocessing, feature engineering, model training, and deployment, with continuous monitoring to optimize performance.
Data Collection and Preprocessing
The foundation of any ML model lies in the quality of the data. Data collection involves gathering relevant datasets from various sources such as databases, APIs, sensors, or web scraping. Once collected, preprocessing transforms raw data into a clean, usable format. This step includes handling missing values, removing duplicates, normalizing numerical features, and encoding categorical variables. Data preprocessing ensures consistency and reduces noise, making the data suitable for analysis and modeling.
Feature Engineering and Selection
Feature engineering involves creating new variables or transforming existing ones to better represent the patterns in the data. Techniques include scaling, encoding, and generating interaction terms. Feature selection, on the other hand, focuses on identifying the most relevant features that significantly impact the model’s performance. Methods such as recursive feature elimination (RFE) or using statistical measures like mutual information help in selecting features that improve accuracy and reduce computational complexity.
Model Training and Evaluation
Model training is the process of teaching the algorithm to recognize patterns in the data by optimizing its parameters. During this stage, the training dataset is used to fit the model using techniques like gradient descent or backpropagation for neural networks. Evaluation ensures that the model generalizes well to new data, typically using techniques such as cross-validation, confusion matrices, or metrics like accuracy, precision, recall, and F1 score. This step often involves fine-tuning hyperparameters to strike a balance between underfitting and overfitting.
Deployment and Monitoring
Once a model performs optimally, it is deployed into a production environment to make real-time predictions or automate tasks. Deployment may involve integrating the model with APIs or cloud platforms for scalability. Monitoring ensures the model continues to perform as expected, even with changing data patterns or external conditions. Continuous monitoring involves tracking key performance indicators (KPIs) and retraining the model periodically to address data drift or evolving requirements, ensuring long-term reliability and efficiency.

Core Techniques and Algorithms
Machine learning utilizes a wide array of techniques and algorithms, each designed to address specific problem types. Among these are regression, classification, clustering, and neural network-based methods. Each technique plays a critical role in deriving insights, making predictions, or automating tasks in various domains.
Regression
Regression is fundamental for predicting continuous outcomes and understanding relationships between variables. Linear regression models a straight-line relationship between input variables and outputs by minimizing error, making it ideal for applications such as forecasting sales or analyzing market trends. Logistic regression, while similar in concept, is used for classification tasks where the output is binary. It models the probability of an event occurring, often applied in fraud detection, medical diagnosis, or binary decision-making processes.
Classification
Classification algorithms are used to categorize data into predefined groups. Support Vector Machines (SVM) are powerful tools for high-dimensional classification tasks, effectively separating data points using hyperplanes. They are widely used in text categorization and handwriting recognition. Decision trees provide an intuitive, tree-like structure to split data based on feature values, often employed in credit scoring and customer behavior analysis. Naïve Bayes classifiers, rooted in Bayes’ Theorem, are computationally efficient and effective for tasks like email spam filtering and sentiment analysis, assuming independence between predictors.
Clustering
Clustering techniques, on the other hand, are used to group similar data points without predefined labels. K-means clustering is one of the most popular methods, dividing data into kkk clusters by minimizing the variance within each group. This technique is commonly used in customer segmentation and market analysis. Hierarchical clustering builds a tree-like structure (dendrogram) to illustrate nested clusters, making it valuable for understanding relationships within datasets, such as in genomic data analysis or social network visualization.
Neural networks
Neural networks and deep learning represent advanced ML techniques for handling complex datasets. Neural networks consist of layers of interconnected nodes (neurons) that process input data to learn patterns, excelling in tasks like facial recognition and predictive maintenance. Deep learning, a subset of neural networks with multiple hidden layers, enables the hierarchical learning of features, making it suitable for large-scale data challenges. It drives breakthroughs in fields such as natural language processing (NLP), autonomous driving, and advanced medical imaging. Techniques like backpropagation and gradient descent are key to training these networks, ensuring they adapt to intricate data and evolving requirements.

Challenges in Machine Learning
While machine learning offers transformative potential, it comes with a host of challenges that can hinder model development, deployment, and adoption. Addressing these challenges is crucial to building reliable and effective systems.
Common Challenges: Overfitting, Underfitting, Data Bias
One of the most common issues in machine learning is overfitting, where a model performs exceptionally well on training data but fails to generalize to unseen data due to excessive complexity. This often occurs when models capture noise instead of true patterns. On the other hand, underfitting happens when a model is too simplistic to capture underlying trends, leading to poor performance on both training and test data. Another critical issue is data bias, where imbalanced or unrepresentative datasets lead to biased predictions. For instance, a facial recognition model trained on limited demographic data might perform poorly across diverse populations. Such biases can result in unfair or discriminatory outcomes, especially in sensitive applications like hiring or law enforcement.
Ethical Considerations in ML
Ethical challenges in machine learning are becoming increasingly prominent. Algorithmic bias arises when historical or training data reinforce existing inequalities, leading to discriminatory results. For example, biased credit scoring models might unfairly deny loans to specific groups. Privacy concerns also pose significant risks, particularly when dealing with personal or sensitive data. Techniques such as differential privacy and federated learning are being developed to mitigate these concerns, but ensuring compliance with data protection regulations like GDPR and CCPA remains a challenge. Organizations must also address the transparency of ML models, as the “black box” nature of some algorithms makes it difficult to explain or justify decisions.
Scalability and Computational Power Limitations
Machine learning models often require significant computational resources, especially for large-scale applications like deep learning. Training neural networks with millions of parameters demands substantial hardware capabilities, including GPUs or TPUs, which can be expensive and inaccessible to smaller organizations. Additionally, as datasets grow in size and complexity, maintaining scalability becomes challenging. Distributed computing and cloud-based ML platforms offer solutions but introduce their own challenges, such as ensuring consistent performance across nodes and managing data synchronization. Efficiently scaling models while balancing cost and performance remains a critical hurdle for ML practitioners.
Applications of Machine Learning
Machine learning (ML) is transforming industries by enabling intelligent data analysis, pattern recognition, and decision-making. In healthcare, ML enhances diagnostics by analyzing medical images, predicting disease progression, and personalizing treatment plans, while also accelerating drug discovery. The finance sector leverages ML for real-time fraud detection, credit risk assessment, and algorithmic trading, improving decision-making and efficiency. E-commerce platforms utilize ML for personalized recommendations, dynamic pricing, and optimized inventory management, enhancing user experiences and operational performance.
In manufacturing, ML-driven predictive maintenance minimizes downtime, and quality control systems ensure consistency using computer vision. Autonomous vehicles and logistics benefit from ML’s role in route optimization, demand forecasting, and real-time tracking. Marketing teams use ML for hyper-personalized campaigns, sentiment analysis, and predictive ad targeting, improving customer engagement. In the energy sector, ML optimizes smart grids, predicts consumption patterns, and enhances renewable energy efficiency. Across industries, ML delivers scalable, data-driven solutions that drive innovation, efficiency, and accuracy.
Future Trends in Machine Learning
As machine learning continues to evolve, several key trends are shaping its future, driving innovation, and addressing existing challenges. These trends aim to make ML more interpretable, efficient, and seamlessly integrated with emerging technologies.
Explainable AI (XAI)
Explainable AI (XAI) focuses on making machine learning models more transparent and interpretable, addressing the “black box” nature of complex algorithms like deep neural networks. This is particularly critical in industries such as healthcare and finance, where understanding the rationale behind predictions is essential for trust and compliance. Techniques like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) are gaining prominence, enabling stakeholders to identify biases, validate decisions, and enhance accountability in AI-driven systems.
MLops and Automated Machine Learning (AutoML)
MLops (Machine Learning Operations) is transforming how ML models are deployed, monitored, and maintained in production environments. By automating workflows, MLops ensures that models remain reliable and scalable as data evolves. Complementing this is Automated Machine Learning (AutoML), which simplifies the development process by automating tasks like feature selection, model tuning, and hyperparameter optimization. AutoML democratizes ML by enabling non-experts to build robust models, accelerating adoption in small and medium enterprises (SMEs) and reducing time-to-market for ML solutions.
Integration with Other Technologies
The integration of ML with other technologies is driving new use cases and expanding its impact. In the Internet of Things (IoT), ML analyzes data from connected devices to predict failures, optimize performance, and enable real-time decision-making in areas such as smart homes and industrial automation. At the edge computing level, ML models are being deployed closer to data sources, reducing latency and enabling faster insights, which is crucial for applications like autonomous vehicles, remote healthcare, and augmented reality. This synergy between ML and emerging technologies ensures smarter, more responsive systems that are optimized for real-world environments.
Conclusion
Machine learning has emerged as a cornerstone of modern technology, driving innovation and solving complex problems across diverse industries. From enhancing healthcare diagnostics and financial security to revolutionizing e-commerce and manufacturing, ML’s applications are vast and transformative. Its ability to process vast amounts of data, learn from patterns, and make intelligent decisions has positioned it as an indispensable tool in addressing today’s technological challenges.