What is a Deepfake? Deepfakes are synthetic media—such as videos, images, or audio—created using advanced artificial intelligence (AI) and machine learning techniques to manipulate or generate realistic, yet entirely fabricated, content. The term “deepfake” combines “deep learning,” a subset of machine learning, with “fake,” reflecting how these technologies are used to produce content that appears authentic but is entirely artificial. Deepfakes can be used to swap faces in videos, clone voices, or even create entirely new scenarios that seem indistinguishable from real life.
Creating a deepfake typically begins with collecting a large dataset of images, videos, or audio of the subject to be replicated. These datasets provide the foundation for training a machine learning model, often a Generative Adversarial Network (GAN), which learns to mimic the subject’s appearance, voice, and behaviors. The model is then trained through an iterative process where one network (the generator) creates synthetic content, while another network (the discriminator) evaluates its authenticity. This feedback loop helps refine the generator’s ability to produce increasingly realistic fakes. Once trained, the model can generate new content—whether it’s swapping faces in a video, synthesizing speech, or generating entirely new scenarios—while maintaining a high level of realism. Deepfakes are then often enhanced with post-processing techniques to refine details like lighting, facial expressions, or lip-syncing, making them even harder to distinguish from real content.
How Deepfakes Work: The Technology Behind Them

Explanation of GANs
Generative Adversarial Networks (GANs) are the cornerstone of deepfake technology. GANs consist of two neural networks: the Generator and the Discriminator. The Generator is tasked with creating synthetic data (images, videos, or audio) that closely mimics real-world content. The Discriminator, on the other hand, evaluates the generated content and distinguishes it from real data.
These two networks engage in a competitive process: the Generator continually improves its output to make it more realistic, while the Discriminator sharpens its ability to identify fakes. Over time, this adversarial training results in the Generator learning to create highly convincing content that is often indistinguishable from genuine media. This process is iterative, with both networks improving through constant feedback, making GANs particularly effective in generating deepfakes.
The Process of Training a Model
Training a model to generate deepfakes involves feeding a GAN large datasets of real images, videos, or audio samples of the target subject. In the case of video deepfakes, this means thousands of frames of a person’s face from different angles, lighting conditions, and expressions. The model learns to capture key features—like facial expressions, movements, and speech patterns—by comparing the synthetic content generated by the Generator with the actual data in the training set.
The Generator creates fake content, and the Discriminator evaluates its realism, providing feedback that helps the Generator refine its output. As the model undergoes multiple iterations, the Generator becomes increasingly skilled at producing convincing deepfakes. For video content, this includes mastering details such as facial recognition, lip-syncing, and body movements. In the case of audio, the model learns to replicate speech patterns, tone, and pitch, making the synthesized voice sound more natural and realistic.
Role of Data
The quality of a deepfake is largely determined by the training datasets used to teach the model. A comprehensive dataset includes a large variety of images, videos, or audio recordings that capture the target subject in various conditions—different angles, lighting, facial expressions, and more. This diversity is essential for the model to generate convincing deepfakes in different contexts. However, raw data often needs to be enhanced through data augmentation techniques to improve the model’s performance and generalization.
Data augmentation involves transforming the original dataset by introducing variations such as rotating images, altering lighting conditions, adding noise, or adjusting colors. This process allows the model to better handle diverse real-world scenarios and improve its ability to generate high-quality deepfakes. For example, augmenting a facial image dataset with different expressions and angles helps the model replicate more natural-looking facial movements in a video. Similarly, augmenting audio data by altering pitch, speed, and background noise helps the model create more lifelike voice deepfakes. In this way, data augmentation is crucial in expanding the dataset and enhancing the overall quality of the generated content.

Types of Deepfakes
Video Deepfakes
The most common technique is face swapping, where the facial features of one person are transferred to another in a video. This is done by isolating facial landmarks (such as eyes, nose, mouth, and jawline) and replacing them with a corresponding face from a different video or image. In more sophisticated deepfakes, full-body generation involves the manipulation of not only the face but the entire body of the subject.
To achieve this, motion capture and pose estimation models are used, which track and replicate the body’s movements, ensuring that the altered video retains natural movement and body language. These models often rely on 3D mesh generation techniques, where the subject’s 3D shape is recreated, allowing for realistic changes in posture and actions. Post-processing techniques like color correction and lighting adjustment are also applied to ensure seamless integration of the new facial features or body parts into the video’s original environment.
Audio Deepfakes
Audio deepfakes focus on replicating a person’s voice by training AI models on large datasets of their spoken words. The core technology for voice cloning involves neural networks, specifically recurrent neural networks (RNNs) or WaveNet-based architectures, which excel at generating sequences like speech. The model learns a person’s unique speech characteristics, such as pitch, cadence, intonation, and rhythm, by analyzing their voice recordings. Voice replication works by mapping the learned voice features onto new text or speech input, generating synthetic audio that closely mimics the target’s voice.
In speech synthesis, the model generates entirely new spoken sentences in the target’s voice using text-to-speech (TTS) techniques, often leveraging a sequence-to-sequence model to convert input text into audio. Advanced methods like speaker embedding allow for fine-tuning the model to replicate specific vocal nuances, even under varying emotional states or speech conditions. These audio deepfakes are often generated using autoencoders to compress and then reconstruct voice features, which helps in capturing and reproducing the finer details of speech.
Image Deepfakes
Image deepfakes primarily use convolutional neural networks (CNNs) and other generative models to alter or create images. In face-swapping techniques, the target’s facial features are extracted using a facial recognition algorithm and then replaced with those of another individual, ensuring proper alignment of the eyes, mouth, and facial contours. This is often done using autoencoders or GANs, where the encoder part of the network encodes the target face into a latent space, and the decoder generates the new face.
Data augmentation is frequently applied to improve the quality of these deepfakes, involving transformations such as rotations, shifts, and color changes to the target faces to make them appear more realistic and to improve generalization. Additionally, deepfake creators use style transfer techniques, which enable them to apply the texture and characteristics of one face to another, adjusting features like skin tone and wrinkles to match the new face’s surroundings. High-resolution GANs (HRGANs) are also used to generate images with photorealistic quality, even down to fine details like lighting, shadow, and skin texture. These manipulations are often complemented by post-processing steps such as seamless blending and feathering to ensure that the altered images appear cohesive and natural.
Deepfakes in the Context of Cybersecurity and Fraud
Potential Threats to Identity and Security
Many people still don’t know what is a deepfake, yet this technology introduces significant threats to identity and security by enabling cybercriminals to impersonate individuals with remarkable precision. As deepfake technology advances, traditional security systems—such as facial recognition, voice biometrics, and two-factor authentication (2FA)—become vulnerable to manipulation. Cybercriminals can use deepfakes to bypass these systems and gain unauthorized access to sensitive data or systems.
For example, a deepfake video or audio clip of a company executive can be used to manipulate employees into transferring funds, sharing confidential documents, or revealing access credentials. In the context of personal security, deepfakes can be used to steal identities, allowing criminals to commit fraud or access financial accounts by mimicking a person’s likeness or voice.
Countries per region with biggest increases in deepfake-specific fraud cases from 2022 to 2023 (in %).
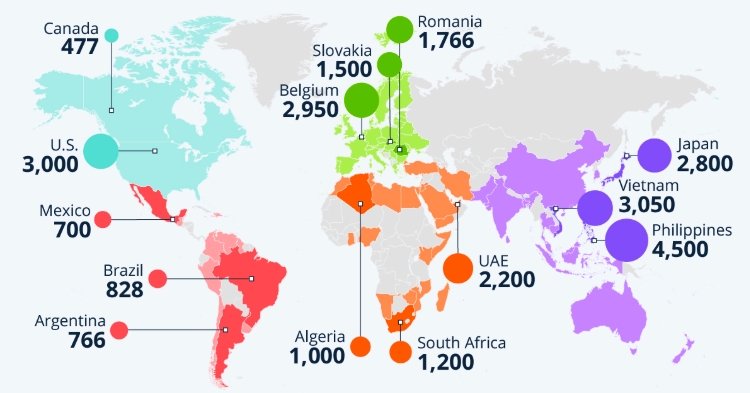
Examples of Fraud and Impersonation
The use of deepfakes for fraud and impersonation is on the rise, with numerous high-profile cases already demonstrating the potential for abuse. One common example is CEO fraud or business email compromise (BEC), where attackers use deepfake voice technology to impersonate a company executive and instruct employees to perform financial transactions, such as transferring funds or providing sensitive information.
Another example is fake video conferencing, where deepfake technology can be used to create convincing video calls, allowing criminals to impersonate key figures and manipulate others into divulging confidential information or authorizing financial activities. Deepfakes have also been used in romance scams, where synthetic images or videos are created to lure victims into sending money or personal information by pretending to be someone they trust. Misinformation and fake news campaigns are another risk, where deepfake videos are used to spread false narratives or manipulate public opinion, making it difficult to distinguish fact from fiction.
Concerns of internet users regarding the potential influence of AI and deepfakes in upcoming elections worldwide in 2024, by country
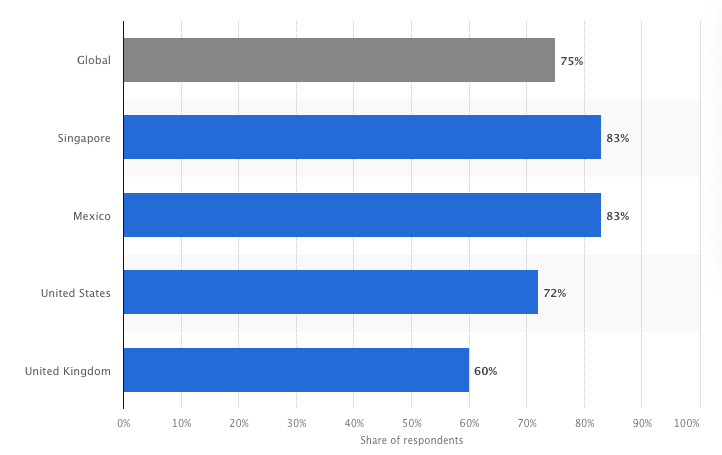
Measures Companies and Individuals Should Take
To protect against the risks posed by deepfakes, both companies and individuals must implement proactive security measures. First, businesses should integrate deepfake detection tools into their security infrastructure. These AI-powered tools can analyze video, audio, and images for signs of manipulation, such as inconsistencies in lighting, lip-syncing, or voice patterns. Multi-factor authentication (MFA) is another essential defense, as it adds an additional layer of security beyond facial or voice recognition. Companies should also deploy advanced biometric systems with liveness detection, which ensures that facial recognition systems are interacting with a real person and not a deepfake.
Employee training is crucial to help individuals recognize phishing attempts and fraudulent requests that could be driven by deepfake technology, especially when dealing with sensitive financial transactions or requests for personal information. For individuals, exercising caution when engaging in online communication—especially with unfamiliar voices or faces—can help avoid deepfake-based scams. Regularly monitoring personal accounts, using strong and varied passwords, and avoiding sharing sensitive information through unverified channels are also critical steps in minimizing exposure to deepfake-based fraud. By combining technological solutions with awareness and vigilance, both companies and individuals can reduce the threat posed by deepfakes in cybersecurity.
The Future of Deepfakes
Advancements in AI and Generative Adversarial Networks (GANs) will make deepfakes increasingly realistic and harder to detect. As computational power grows, deepfakes could become indistinguishable in real-time applications like video calls and live broadcasts. Personalized, high-quality synthetic media will become more accessible, creating new opportunities in entertainment and virtual reality, while also raising concerns about cybercrime, fraud, and disinformation.
To counter these advancements, deepfake detection technologies will evolve with more powerful machine learning models capable of identifying deeper inconsistencies in media. Future solutions may incorporate technologies like blockchain for media verification, ensuring authenticity and preventing tampering. As deepfake creation becomes more sophisticated, detection systems must continually adapt.
Companies like DeepQ will be pivotal in shaping the future of deepfake technology. By advancing AI-driven detection and forensic analysis, DeepQ is helping to combat the risks posed by deepfakes, ensuring organizations can stay ahead of emerging threats. Their work will be critical in defining how society addresses the challenges of synthetic media.